

La herramienta OmniVoice permite clonar voces y generar audio a partir de texto mediante inteligencia artificial. Este proyecto facilita la creación de locuciones realistas con muestras mínimas de audio original. Los usuarios pueden ejecutar el sistema localmente con una tarjeta gráfica básica para procesar el contenido de forma gratuita.
El avance de estos modelos reduce la fiabilidad de la comunicación por voz como método de autenticación. Aunque el proceso técnico es sencillo, su accesibilidad plantea retos éticos sobre el uso responsable de la tecnología. La facilidad para replicar voces conocidas exige una mayor cautela al verificar la información recibida.
Hasta hace poco nos daba cierta seguridad escuchar a una persona a la que conocíamos hablar y eso nos permitía «autentificar» el origen de la comunicación. Si escuchábamos a alguien conocido que nos hablaba considerábamos que eso era más fiable que cuando recibíamos mensajes escritos… Hasta ahora.

El avance de los modelos de IA nos ha llevado hasta un punto en que cualquiera teniendo una mísera muestra de una voz puede hacer que esa voz diga lo que queramos, pero es que, además, ahora podemos hacerlo gratis si tenemos una GPU medianamente decente. Os voy a comentar lo que tenéis que hacer, pero, por favor, tened cuidado de para qué lo usáis que, francamente, a mi me da bastante miedo.
El proyecto del que vamos a hablar es omnivoice, que nos permite de manera sencilla clonar y generar voces en base a texto. Os comento los pasos más sencillos y luego ya podréis experimentar lo que queráis. El repositorio es este: https://github.com/k2-fsa/OmniVoice
Prerrequisitos
Antes que nada decir que se requiere tener una GPU que pueda almacenar al menos 2Gb de VRAM, en mi caso lo he probado con una RTX 3090 y me sobraba memoria (eso si, tuve que parar el servidor de llama.cpp que tenía corriendo con otro modelo que llenaba la VRAM).
También sería conveniente tener un sistema operativo de verdad (yo lo he probado con cachy os) pero si no tenéis otra cosa que no sea windows también vais a poder hacerlo.
Instalación
Yo utilicé el método de uv, ya que ésta es una herramienta que ya tengo instalada y uso mucho. Los pasos a dar serían:
git clone https://github.com/k2-fsa/OmniVoice.git
cd OmniVoice
uv sync
Una vez que lo tienes ya puedes lanzar la web de demo que va a ser la que más fácil te va a permitir clonar sin tener que programar.
uv run omnivoice-demo --ip 0.0.0.0 --port 8001
Y si todo ha ido bien ya podréis acceder a http://localhost:8001 y ver esta pantalla:
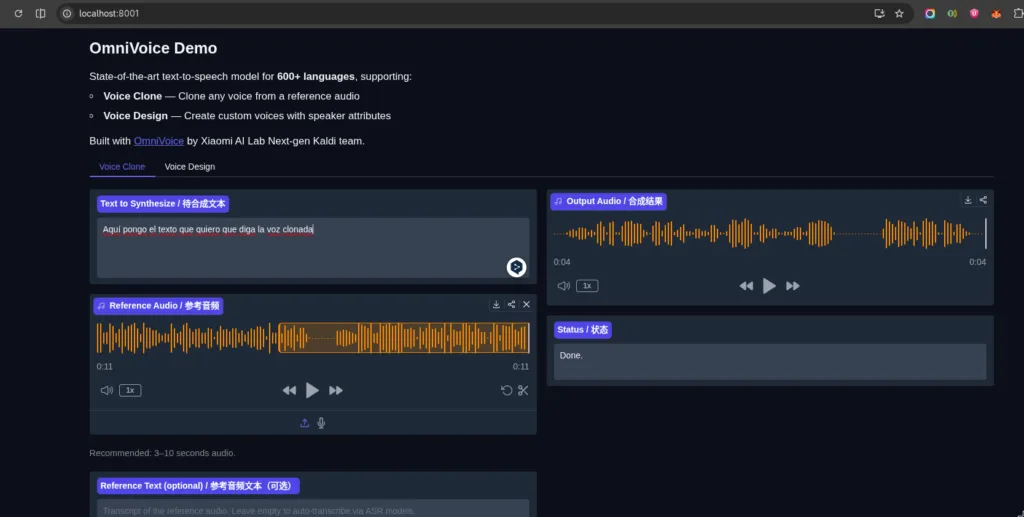
Clonando
El método más sencillo y que a mi me ha funcionado a la perfección es, simplemente, descargarse una muestra de varios segundos de una persona hablando normalmente y subirla a «Reference Audio», seleccionar el idioma (aunque acierta siempre) y rellenar el texto que queremos que diga.
Luego simplemente pulsamos el botón para generar y en muy pocos segundos veremos que se rellena el output audio
Luego ya podéis exportarlo y hacer con él lo que queráis… Pero sed buenos y no hagáis maldades. Os dejo aquí un ejemplo: