Ya vimos en el anterior post cómo instalar el agente opencode que nos va a permitir utilizar distintos proveedores de IA en nuestros flujos de trabajo (en concreto a mi para programar, pero quien sabe para qué querréis usarlos vosotros), vimos cómo configurarlo con un proveedor externo (por tanto de pago), pero nada nos impide utilizar un proveedor local (si tenéis una tarjeta con GPU solo tenéis que seguir algunos de mis posts al respecto) y ya tendréis un ollama operativo del que tirar. Así que, si cumplís los requisitos vamos a ver cómo configurar nuestra instalación de opencode para dejar de gastar dinero en proveedores externos y usar nuestra propia GPU.
No hay una forma «gráfica» de configurar el modelo, así que vamos con las instrucciones para hacerlo de manera manual:
Crea el archivo opencode.jsonc (en mi caso en ~/.config/opencode ). si habéis seguido la guía de instalación previa os sonará porque es donde hemos metido la configuración mcp
En este caso hemos supuesto que tenemos el servidor ollama corriendo en nuestra propia máquina y el modelo que hemos elegido es qwen3… Pero eso tiene cierto truco, si usas el modelo tal cual te lo bajas no va a funcionar porque el contexto en ollama para este modelo es demasiado pequeño, antes tienes que hacer esto:
docker exec -it ollama bash
# ollama run qwen3:latest
>>> /set parameter num_ctx 16384
Set parameter 'num_ctx' to '16384'
>>> /save qwen3:latest-16k
Created new model 'qwen3:8b-16k'
>>> /bye
Si todo ha ido bien, cuando abras opencode en cualquier proyecto ya podrás elegir este modelo:
Y, dependiendo de los recursos de tu máquina podrás disfrutar de todas las ventajas de un modelo local. Eso si, para utilizar las capacidades de opencode aseguraos de que el modelo que estéis usando tenga capacidades para tools y thinking. Podéis verlo, por ejemplo con este modelo de nvidia (si tienes 20Gb de memoria en tu GPU es un buen candidato):
Es posible que, aunque tenga acceso a tools no nos permita ejecutar cosas tan simples como listar un directorio o editar un archivo. Eso es debido a que no está accediendo a las herramientas propias de opencode. He tenido que hacer algunos malabares para hacer funcionar algunos modelos concretos, así que dejo en vuestras manos el poder sacar lo mejor del sistema… Sin tener que pagar a otros proveedores ni enviarles información igual demasiado privada.
Como ya contamos en una entrada anterior La IA más barata para generar código, podemos utilizar claude code con otras IAs además de las de Anthropic, y esto es muy bueno porque nos da muchas herramientas de agente inteligente como la nada despreciable posibilidad de conectar con servidores MCP.
Para este ejemplo vamos a utilizar outline, que, para el que no lo conozca, es un excelente editor de documentos al estilo notion y que yo uso, junto con mi equipo, para dejar la documentación de los proyectos y ahora vamos a ver cómo podemos integrar esta documentación con nuestra IA favorita para programar.
Lo primero que tenemos que hacer es conseguir una clave de API en outline. Eso se consigue en la ruta /settings/api-and-apps donde pediremos crear una nueva clave api
Una vez creada más vale que os la copieis rápido porque no vais a poder volver a recuperarla después.
Una vez que tenemos instalado claude code y sus prerequisitos (que podéis ver en la entrada anterior) tendremos en nuestra raíz de usuario un archivo llamado .claude.json que tiene, entre otras cosas, las definiciones de los mcp.
Yo lo he añadido bajo la línea «mcpContextUris»: [] dentro de uno de los proyectos donde lo quiero usar. Evidentemente para usar este mcp necesitas tener docker instalado (doy por hecho que si estás aquí eres de los míos y lo usas diariamente).
Una vez que has grabado el archivo y arrancas claude en el directorio del proyecto en cuestión le puedes preguntar por la lista de mcps:
$ claude mcp list
Checking MCP server health...
outline: docker run -i --rm --init -e DOCKER_CONTAINER=true -e OUTLINE_API_KEY -e OUTLINE_API_URL biblioeteca/mcp-outline - ? Connected
Y ya puedes hacer que la magia surja…
Y darle que si a todos los permisos que pida
Y ya podrías pedirle que te lea documentos como requisitos para programar o que, como en este caso, que nos documente el api que acabamos de construir en el proyecto
¿puedes crear un documento llamado API DocuFactu en esa colección con la documentación sobre el API (solo la parte verifactu) que incluya ejemplos de uso usando una APIKEY?
Y este es el resultado… (solo parte)
Como todo lo que hace la IA luego alguien que sepa tiene que retocarlo y corregirlo (aquí también se puede inventar cosas), pero el caso es que ya tenemos mucho trabajo adelantado.
Hay miles de mcp con los que podemos interactuar por ahí… Solo tienes que buscarlo o, sino, construir el tuyo propio que, igual, lo hacemos aquí cuando tengamos un rato.
Como ya vimos en la anterior entrada es bastante sencillo instalar un sistema SSO como authentik en nuestra infraestructura. De todas formas, crear un login centralizado no es más que una manera de tener que recordar menos contraseñas, pero el objetivo final es no tener que recordar más que unas pocas para poder acceder a todos los servicios, ¿qué hacemos si ya tenemos cuenta en alguno de los servicios más populares como office 365 o google? Lo suyo sería poder hacer login con estas credenciales en cualquier servicio, sea online o sea auto hospedado. Por suerte, authentik puede hacer uso de estos servicios externos de autenticación de manera «relativamente» sencilla. En este post os voy a explicar paso a paso (que sobre todo la parte a realizar con office es un poco liosa) cómo integrar el login de office 365 con authentik y así poder usarlo para acceder a nuestras aplicaciones (eso ya lo explicaremos en próximos posts).
Para poder realizar este tutorial debes tener:
Servidor authentik instalado y configurado (con acceso como administrador)
Cuenta de administrador office365 de tu organización
Un poco de paciencia (esto nunca viene mal)
Paso 1: registrar una aplicación de microsoft entra
Entramos como administrador en portal.office.com
Pedimos que nos muestre todas las opciones (estos de MS suelen ocultarnos cosas)
Seleccionamos la opción Identidad (nos llevará a entra)
Seleccionamos la opción Registro de aplicaciones
Y seleccionamos Nuevo registro
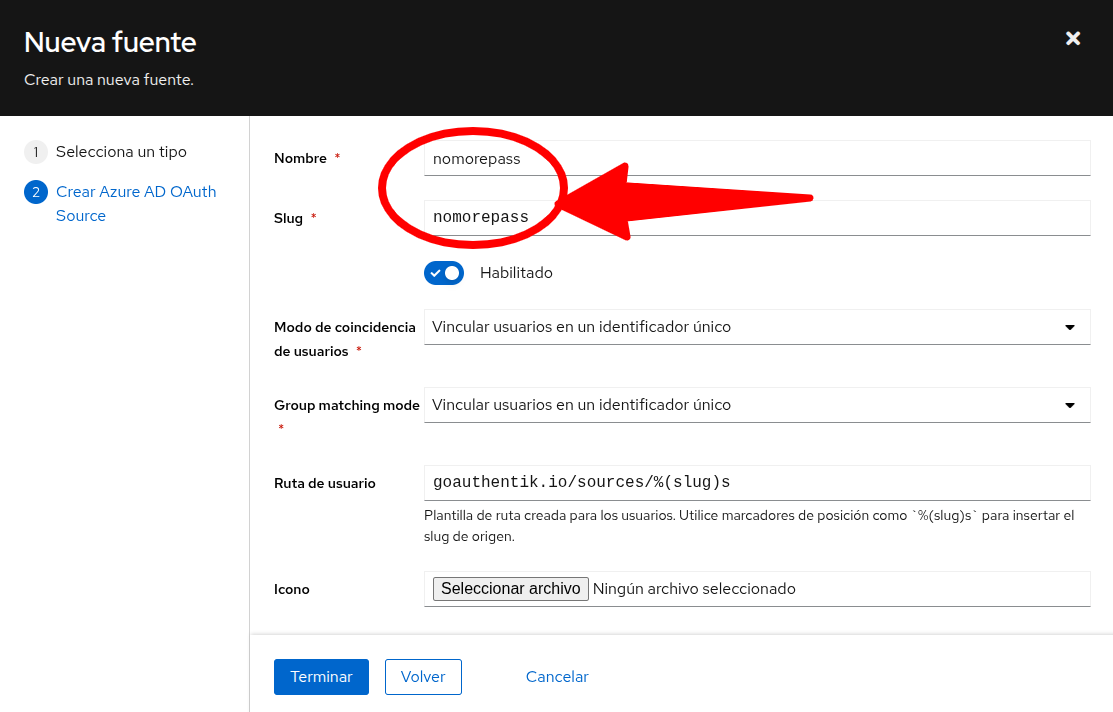
Y rellenamos los datos básicos (yo voy a llamar authentik a la nueva aplicación)
Hemos elegido que solo se pueda entrar con cuentas de nuestra organización, que será lo normal, aunque si queremos que cualquiera que tenga una cuenta de office365 pueda hacer logn tendremos que escoger una de las otras opciones. Atento a la ui de redirección, en principio tendrá el formato https://<direccion-de-tu-authentik>/source/oauth/callback/<nombre-de-fuente> Si no lo configuras ahora lo podrás hacer después cuando termines la configuración en authentik.
Anotamos los datos que vamos a necesitar de la aplicación y creamos un nuevo secreto:
Es muy importante que copiemos el valor del secreto que lo vamos a necesitar luego
El valor del secreto no se va a poder copiar en otro momento, mejor que lo guardes ahora.
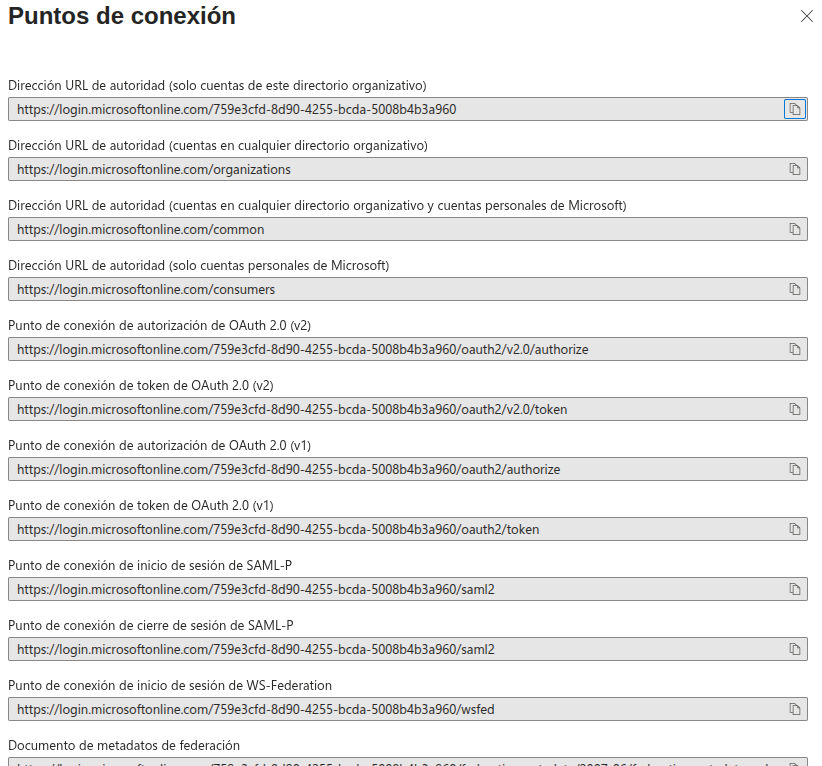
Con esto hemos terminado (en principio) con la configuración necesaria en el portal de office. Lo que hemos hecho, básicamente, es configurar los endpoints de oauth2 que podemos consultar en la opción.
Paso 2: crear un nuevo login social
Las siguientes acciones las haremos como administrador en nuestro servidor authentik
El primer paso es crear un inicio de sesión federado
del tipo azure AD
Ahora deberemos introducir todos los datos que hemos guardado al crear la aplicación en entra:
Los endpoint serán como estos (revisar los que vimos en la pantalla del portal de office):
Y damos a terminar por ahora. Esto nos configura el método para entrar usando las credenciales de Microsoft, pero todavía nos falta un par de cosas para que sea útil del todo.
Paso 3: mapeo de atributos
Ahora necesitamos hacer la equivalencia entre los atributos que vienen de office con los que nosotros vamos a utilizar en nuestro directorio, para eso crearemos una política de expresión:
La llamamos (por ejemplo) azure-ad-mapping y ponemos este contenido:
# save existing prompt data
current_prompt_data = context.get('prompt_data', {})
# make sure we are used in an oauth flow
if 'oauth_userinfo' not in context:
ak_logger.warning(f"Missing expected oauth_userinfo in context. Context{context}")
return False
oauth_data = context['oauth_userinfo']
# map fields directly to user left hand are the field names provided by
# the microsoft graph api on the right the user field names as used by authentik
required_fields_map = {
'name': 'username',
'email': 'email',
'given_name': 'name'
}
missing_fields = set(required_fields_map.keys()) - set(oauth_data.keys())
if missing_fields:
ak_logger.warning(f"Missing expected fields. Missing fields {missing_fields}.")
return False
for oauth_field, user_field in required_fields_map.items():
current_prompt_data[user_field] = oauth_data[oauth_field]
# Define fields that should be mapped as extra user attributes
attributes_map = {
'name': 'upn',
'sub': 'sn',
'name': 'name'
}
missing_attributes = set(attributes_map.keys()) - set(oauth_data.keys())
if missing_attributes:
ak_logger.warning(f"Missing attributes: {missing_attributes}.")
return False
# again make sure not to overwrite existing data
current_attributes = current_prompt_data.get('attributes', {})
for oauth_field, user_field in attributes_map.items():
current_attributes[user_field] = oauth_data[oauth_field]
current_prompt_data['attributes'] = current_attributes
context['prompt_data'] = current_prompt_data
return True
Paso 4: configurar el flujo de alistamiento
Queremos que cualquiera que tenga cuenta en el dominio office pueda entrar a nuestras aplicaciones, por lo que necesitamos registrar los usuarios nuevos cuando entran por primera vez, para ello vamos a crear uun flujo nuevo.
Le ponemos un nombre
Y una vez creado, editarlo, ir a la sección d Vinculaciones de Políticas / Grupos / Usuarios y ahí a Bind existing policy
Y ahí ligar defaultsource-enrollment-if-sso
Ir ahora a vinculos de etapa -> Bind Existing stage
Añadir default-source-enrollment-write (orden 0) y default-source-enrollment-login (orden 10)
Desplegar luego la etapa con orden cero y añadir una política existente azur-ad-mapping que creamos antes:
Por último editarmos la fuente que creamos al principio (Directory -> Federation ..) y le añadimos en la configuración de flujo el flujo de inscrpción a azure-ad-enrollment (o el nombre que le hayamos puesto)
Paso 5: hacer que se vea en el login
Pues ya solo nos faltaría hacer que aparezca una opción para hacer login con este proveedor, esto se hace editando el flujo default-authentication-flow
Y editas la etapa
Y añades desde las fuentes disponibles a Fuentes seleccionadas
Ahora cuando entres en tu authentik ya te aparecerá la opción nueva para acceder. La primera vez que accedas debes aprobar unos permisos especiales a Microsoft:
Ha sido un proceso un poco largo, pero ahora ya tenéis centralizada la información de seguridad y cualquier aplicación que pueda conectarse a authentik podrá usar los usuarios de nuestro dominio… Ahora queda que lo probéis vosotros.
Es posible que, como nosotros, ester harto de tantas contraseñas y tantas veces que tienes que autenticarte para acceder a tus aplicaciones. Nosotros ya inventamos nomorepass para no tener que andar recordando la contraseñas, pero eso no quita a que cada vez que instalamos un nuevo sistema en nuestro laboratorio personal nos toque volver a lidiar con las credenciales de acceso. Hay veces que intentamos centralizarlo en algún proveedor externo (como google o microsoft), pero esto no es del todo seguro y corremos el riesgo de tener que andar configurando nuestras aplicaciones con credenciales que, como las de Microsoft Hello caducan cada cierto tiempo.
Por eso os propongo algo mejor, ¿porqué no hospedar nosotros nuestro propio sistema de autenticación? En este post vamos a ver como instalar y configurar uno de los más populares y potentes sistemas SSO: Authentik. La instalación es bastante sencilla y está bien explicada en su documentación. Os resumo cómo quedaría la cosa. Necesitamos:
Servidor donde instalarlo (2VCPU / 2Gb memoria mínimo)
Docker y docker compose (v2 mejor)
wget y openssl instalado (necesarios solo para la instalación)
Una vez que tenemos el servidor con docker y docker compose instalado nos descargamos la plantilla:
wget https://goauthentik.io/docker-compose.yml
Y generamos los elementos de seguridad necesarios y los guardamos en el archivo .env
Con esto ya podemos arrancar el servidor. Hay cosas que sería recomendable configurar, como la salida de email, bien con un servidor propio, o podéis utilizar cualquier servicio que os ofrezca smtp. También se puede cambiar el puerto por el que se accede, que generalmente está en el 9000/9443 para cambiarlos a los estándar 80/443. Como ejemplo os dejo mi docker-compose y mi .env (cambiando las cosas privadas, claro):
PG_PASS=<esto-lo-tienes-que-generar>
AUTHENTIK_SECRET_KEY=<esto-lo-generas-tambien>
AUTHENTIK_ERROR_REPORTING__ENABLED=true
# SMTP Host Emails are sent to
AUTHENTIK_EMAIL__HOST=mail.biblioeteca.net
AUTHENTIK_EMAIL__PORT=587
AUTHENTIK_EMAIL__USERNAME=no-reply@biblioeteca.net
AUTHENTIK_EMAIL__PASSWORD=<el que sea>
AUTHENTIK_EMAIL__USE_TLS=false
AUTHENTIK_EMAIL__USE_SSL=false
AUTHENTIK_EMAIL__TIMEOUT=10
AUTHENTIK_EMAIL__FROM=no-reply@biblioeteca.net
AUTHENTIK_TAG=2025.6.2
Si todo hay ido bien ya puedes arrancarlo:
docker compose up -d
Y ya puedes empezar a configurar tu nuevo SSO navegando a la página:
http://<IP servidor>:9000/if/flow/initial-setup/
Con esto ya tenemos un sistema que nos permite hacer login con los usuarios que queramos… ¿Qué más podemos hacer con este sistema?… Pues un montón de cosas. Quedaos atentos y en los siguientes posts os enseñaré como hacer cosas interesantes como conectar con sistemas externos (como office365 o google) y hacer uso de esas credenciales.
Bueno, cinco minutos es lo que dedicarás a configurar el software, pero luego tendrá que bajarse todo el blockchain y tardará una eternidad y se comerá todo el disco duro que tengamos disponible, pero bueno, vamos a intentar montar un nodo completo bitcoin para testnet (estamos probando) de manera que podamos hacerle consultas sin tener que llamar a otros servicios.
En un próximo post ya os contaré como hacer un explorador completo (con las mismas restricciones de tiempo que este). Por ahora vamos a preparar los materiales. Vamos a necesitar una máquina con ubuntu (o el sistema operativo de vuestra preferencia) y unos 200Gb de disco (para testnet, si queremos la blockchain de mainnet serán como 800Gb). Yo, en mi caso lo he hecho sobre un contenedor ubuntu en proxmox (ya os contaré qué tal con proxmox cuando tenga un rato).
Para crear mi contenedor he usado un script de la comunidad (aqui) pero vosotros podéis usar un ordenador de casa o una máquina virtual que pueda ejecutar docker y docker compose.
Yo la he configurado con 4 CPUs y 4Gb de memoria y me ha servido perfectamente. No os olvidéis de tener los 200Gb disponibles y montados en algún sitio de vuestra máquina. Una vez que tenemos docker y docker compose instalados y funcionando solo tenemos que crear un docker-compose.yml con este contenido:
En este caso nos vamos a bajar una imagen preconfigurada de bitcoin (aunque si no os fiáis siempre podéis compilar la vuestra sacando el Dockerfile de github. Abriremos los puertos 18443 y 18444 para poder acceder al nodo desde fuera (recordad, si tenéis nat hacer una redirección del puerto en el router). Además, tenemos nuestro disco con 200Gb en el directorio /bitcoin-data y lo montamos en /home/bitcoin/.bitcoin en la imagen.
Las siguientes opciones son para ver el log en consola, usar testnet, activar el RPC por rest y enlazarnos con todas las IPs de la imagen. Además, configuramos que se usará un usuario miusuario con password mipass, se ejecutará como servidor y vamos a mantener índices de todo el blockchain…
Y con esto ya podemos lanzarlo:
docker compose up -d
Si todo va bien en unas cuantas (muchas) horas ya tendríamos una copia de la blockchain de testnet y podremos preguntar, por ejemplo, cual es el último bloque (suponiendo que nuestra máquina tenga la IP 192.168.1.55) usando curl, por ejemplo:
Que nos devolvería algo como esto (el número de bloque, obviamente) será distinto en vuestro caso:
{"result":3774033,"error":null,"id":"curltest"}
Y, lo dicho, intentaré que el próximo post sea de cómo hacer un explorador de testnet que podamos utilizar via web… Id preparando más disco duro.
Gestionar el consentimiento de las cookies
Si, es un coñazo, pero tengo que ponerte este aviso sobre las cookies y mi
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu Proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.